

前言
最近看了刘二大人的深度学习课程,又燃起学习的兴趣,所以我就想着重新从头配置一下python的环境,因为之前学的时候就是一知半解的。顺便把cuda,cudnn和anaconda也给弄清楚。另外说一下刘二大人深度学习课程讲的是真的好呢,大家如果想学深度学习的可以去看看。
【《PyTorch深度学习实践》完结合集】 https://www.bilibili.com/video/BV1Y7411d7Ys/?share_source=copy_web&vd_source=fac6f9fc6ad59403bae7877047951d65
原理
因为学习深度学习肯定绕不开英伟达的显卡加速的,要CUDA来调用GPU来加速训练。所以弄清楚GPU,CUDA与cuDNN的关系有利于我们学习深度学习呢,不然每次都云里雾里,不知道为什么没用到GPU加速呢🤣。我参考下面这个视频来进行讲解。
【【PyTorch】B站首个,终于有人把 GPU/ CUDA/ cuDNN 讲清楚了】 https://www.bilibili.com/video/BV15Q4y1i7Bp/?p=2&share_source=copy_web&vd_source=fac6f9fc6ad59403bae7877047951d65
大家也可以看看这个视频来了解的CUDA的发展历程。
第一个问题:为什么深度学习要用到GPU
这个就是因为GPU的并行计算架构非常适配深度学习中的矩阵运算的需求,可以大幅提升训练和推理的效率。这就是为什么我们在学习深度学习的时候通过GPU来加速训练。
第二个问题:当电脑接受到我们写的代码知道要调用GPU时,电脑实际是怎么完成这个过程的
GPU 是显卡中的核心计算部件,最初主要用于图形渲染。由于其内部由大量计算单元组成,结构上天然适合执行大规模并行计算。随着科学计算、深度学习等领域的发展,人们逐渐希望利用 GPU 来分担 CPU 在数值计算方面的压力,以提升整体计算效率。
然而,GPU 并不能像 CPU 一样被操作系统直接当作通用计算单元来调度。CPU 具有完整的控制逻辑和复杂的指令系统,而 GPU 更擅长执行高度并行、结构相同的计算任务。因此,要让程序“用得上”GPU,就需要一套专门的软件机制来完成 GPU 的管理、调度和计算任务的下发。
为了解决这一问题,NVIDIA 推出了 CUDA(Compute Unified Device Architecture)平台。CUDA 本质上是一套面向 GPU 的并行计算编程模型和运行时系统,它为开发者提供了一种规范化的方式,使得程序可以在 CPU 的控制下,可以将计算任务交由 GPU 执行。
CUDA 通过引入 kernel(内核)、thread(线程)和 block(线程块)等概念,将原本在 CPU 上串行执行的计算任务拆分为大量相互独立的子任务,并由 GPU 中成百上千个线程并行执行,从而显著提升计算效率。
CUDA 的底层接口和运行时库主要由 C/C++ 实现。下面给出一个简单的 CUDA 示例程序,其功能是使用 GPU 并行地完成两个长度为 1024 的向量相加,并将计算结果拷贝回 CPU 端进行验证。需要注意的是,CUDA 程序文件的后缀通常为 .cu,并且需要使用 NVIDIA 提供的 nvcc 编译器进行编译。
#include "cuda_runtime.h"
#include <stdlib.h>
#include <assert.h>
#include <iostream>
// Device code(运行在 GPU 上)
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
// Host code(运行在 CPU 上)
int main()
{
int N = 1024;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
float* h_C = (float*)malloc(size);
// Initialize input vectors
for (size_t i = 0; i < N; i++) {
h_A[i] = 1.0f;
h_B[i] = 2.0f;
}
// Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Kernel invocation with N threads
VecAdd<<<1, N>>>(d_A, d_B, d_C);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
for (size_t i = 0; i < N; i++) {
assert(h_C[i] == 3.0f);
}
std::cout << "\t\t\tDONE!" << std::endl;
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
free(h_A);
free(h_B);
free(h_C);
return 0;
}main 函数功能概述
从整体流程来看,main 函数主要完成了以下几个步骤:
- 在 Host(CPU)端申请并初始化数据
- 将 Host 端的数据显式拷贝到 Device(GPU)端显存
- 通过 CUDA kernel 启动 GPU 并行计算
- 将 Device 端的计算结果拷贝回 Host 端进行验证
这是一个最基础的 CUDA 使用示例,用于展示 CPU 如何通过 CUDA 调用 GPU 完成并行计算任务。
补充说明与总结
需要说明的是,上述示例中仅使用了最简单的线程配置方式,实际的 CUDA 程序中通常还会引入 grid(网格)、多维 block 等更复杂的组织结构,以适应更大规模和更复杂的计算需求。但是我们只需要理解 CUDA 的基本工作原理就可以了,并不需要深入掌握所有 CUDA 编程细节。
在实际应用中,我们只需要理解以下分工关系即可:
- CPU:负责程序控制、任务调度和逻辑管理
- CUDA:作为 CPU 与 GPU 之间的桥梁,负责内存管理、任务下发和运行时支持
- GPU:负责执行大规模并行计算任务
因此,CUDA 提供的并不是一种“自动加速”的黑盒工具,而是一套完整的并行计算编程规范和运行环境。它使开发者能够将复杂计算问题拆分为大量可并行执行的子任务,并充分利用 GPU 的并行计算能力,从而在科学计算、图像处理和深度学习等领域显著提升计算效率。
最后说一下CUDA 提供的并不是单纯的“加速功能”,而是一套让开发者能够高效利用 GPU 并行能力的编程规范和运行环境,使得复杂计算可以被拆分成大量子任务,并在 GPU 上同时执行,从而显著提升计算效率。
第三个问题:CUDA、CUDA Toolkit 与 cuDNN 是什么关系?
通过前面的讲述,我们已经大致理解了 CUDA 是什么。那么,CUDA Toolkit 又扮演着怎样的角色呢?
CUDA Toolkit 的作用,是为 CUDA 提供其所需的一整套开发工具和运行环境。需要说明的是,CUDA Toolkit 并不是某一个单独的程序,而是 NVIDIA 提供的一整套 CUDA 开发与运行环境,其中包含了 CUDA 编译器(nvcc)、CUDA 运行时库、相关头文件,以及调试与性能分析等配套工具。简单来说,CUDA Toolkit 可以理解为 CUDA 在操作系统中的“实体化实现”,没有它,CUDA 程序既无法被编译,也无法在系统中正常运行。因此,在实际安装过程中,我们从 NVIDIA 官网下载的,通常就是某一版本的 CUDA Toolkit。
在此基础之上,NVIDIA 又针对深度学习这一典型应用场景推出了 cuDNN。cuDNN 是一个构建在 CUDA 之上的高性能计算库,专门对深度学习中常见且计算密集的操作(如卷积、池化、激活函数、Batch Normalization 等)进行了高度优化。cuDNN 本身并不引入新的编程模型,而是直接复用 CUDA 提供的并行计算能力,只是将复杂且性能敏感的 CUDA 实现封装成了更易于调用的接口。
从依赖关系上来看,cuDNN 必须运行在 CUDA 之上,而 CUDA 的正常使用又依赖 CUDA Toolkit 所提供的编译器和运行时环境。因此可以这样理解:CUDA 定义了 GPU 并行计算的核心模型,CUDA Toolkit 提供了这一模型在系统中的实现与运行基础,而 cuDNN 则是在此基础上,面向深度学习场景提供的专业高性能加速库。
总体而言,CUDA、CUDA Toolkit 与 cuDNN 并不是并列的概念,而是自底向上的层级关系。理解它们之间的分工与依赖关系,有助于更清楚地认识 GPU 加速体系在实际工程中的运行方式。也正因如此,在实际安装和配置环境时,需要特别注意 CUDA Toolkit 与 cuDNN 之间的版本对应关系,避免由于版本不匹配而导致 GPU 无法正常使用。
第四个问题:既然 CUDA 是用 C/C++ 实现的,为什么我们用 Python 也能调用 GPU 进行加速?
在前面的内容中我们提到,CUDA 及其相关组件主要是由 C/C++ 实现的。那么在实际使用中,尤其是在深度学习场景下,我们往往编写的是 Python 代码,却同样能够调用 GPU 并获得显著的加速效果,这背后的原因是什么呢?
关键在于:Python 本身并不直接与 GPU 进行计算,而是通过深度学习框架间接调用了底层基于 CUDA 的高性能实现。
以 PyTorch 为例,PyTorch 并不是 GPU 计算能力的来源,而是对 CUDA 生态的一次高层封装。PyTorch 的底层核心由 C/C++ 编写,并通过 CUDA、cuDNN 等库实现了 GPU 上的高效计算逻辑;而 Python 只是作为“接口层”,用于描述计算过程、组织模型结构和调度计算流程。真正运行在 GPU 上的数值计算,依然发生在 CUDA kernel 层。
当我们在 Python 中使用 PyTorch 编写代码时,实际上做的是告诉 PyTorch“要做什么计算”,而不是“如何在 GPU 上一步步计算”。PyTorch 会在内部判断当前是否存在可用的 GPU 环境,如果存在,就会将相应的计算操作映射为对 CUDA 或 cuDNN 的调用,并最终在 GPU 上并行执行。
也就是说,Python 并没有绕过 CUDA,也没有直接控制 GPU,而是站在 PyTorch 这样的框架之上,间接使用了 CUDA 提供的能力。
下面图片中的展示的就是如何将数据拷贝到GPU上和利用GPU加速模型的使用方法,因为本文章只是介绍一下方法,具体的深度学习的整个流程请大家看看刘二大人的深度学习课程呢,非常实用。学到第10课卷积神经网络(基础篇)的时候在视频的最有有讲如何利用GPU进行模型的加速。
【《PyTorch深度学习实践》完结合集】 https://www.bilibili.com/video/BV1Y7411d7Ys/?p=10&share_source=copy_web&vd_source=fac6f9fc6ad59403bae7877047951d65
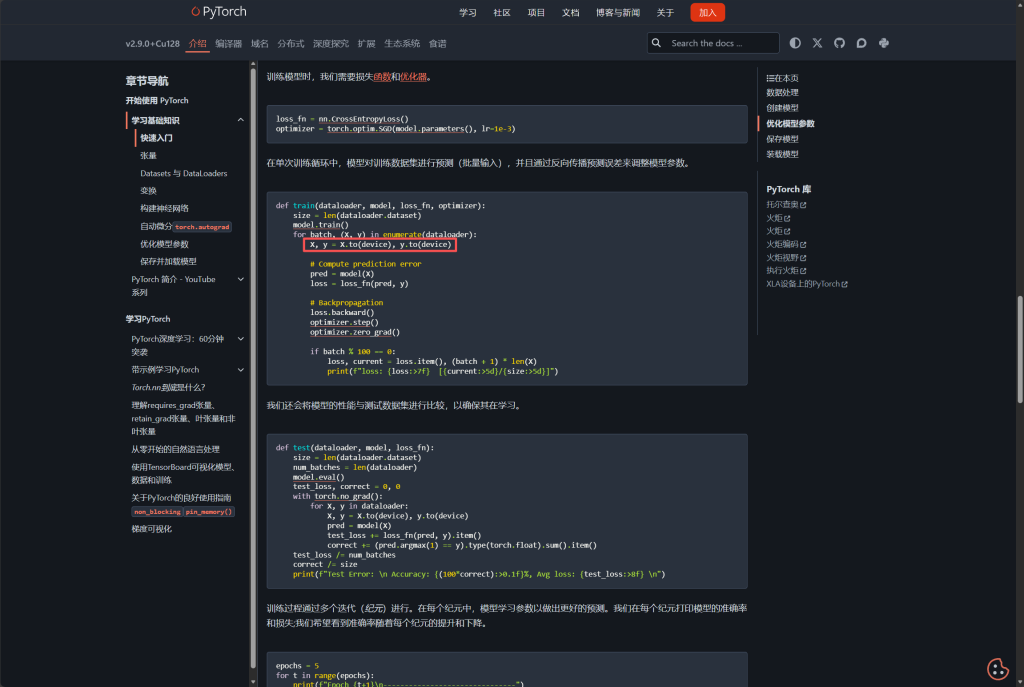
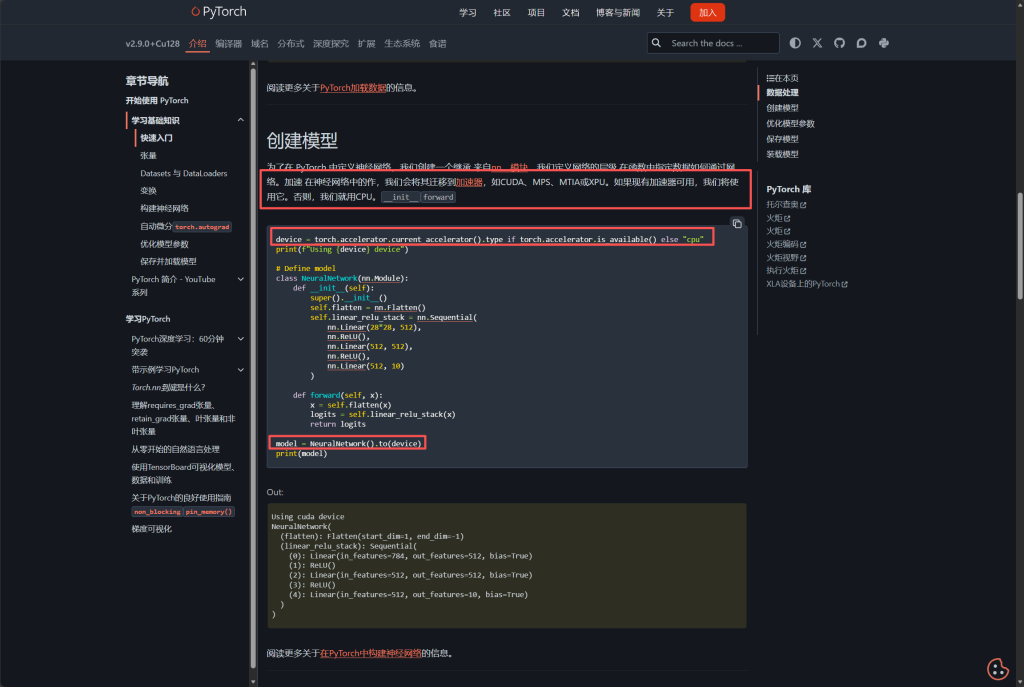
实操
因为是从头开始配置python环境,所以我就打算把anaconda之类的全删掉重新安装。我推荐一个卸载软件叫做geek,这个的免费版就有很强的功能,大家可以试一试。
实操方面我参考了B站的这个教程,因为他在安装的过程中也大致解释了为什么要这样做。
【通关cuda、anaconda、pytorch的安装(深度学习必备基本功)】 https://www.bilibili.com/video/BV1dujdzrEJq/?share_source=copy_web&vd_source=fac6f9fc6ad59403bae7877047951d65
显卡驱动
首先就是要装英伟达的驱动。没有安装英伟达驱动,操作系统只能把显卡当作“通用显示设备”,只有安装了驱动,电脑才真正“认识”并能正确使用英伟达显卡的全部能力。
搜索英伟达,点击驱动程序,找到NVIDIA APP下载就可以下载驱动了。针对于Game Ready Driver(游戏驱动)和Studio Driver(创作者驱动)其实没什么太大区别,都可以下载的,主要区别就是Game Ready Driver 面向新游戏首发和性能优化、更新快但稳定性次之,而 Studio Driver 面向创作与科研场景、更新慢但经过专业软件充分验证、稳定性优先。
看到下面的画面就说明下好了,
右键你电脑底下的任务栏,打开任务管理器选到性能,你看到NVIDIA的显卡就说明驱动安装正确了。顺带说一下这个GPU0是intel的集成显卡。

安装miniconda
我为什么选择安装miniconda,是因为Anaconda 自带大量常用科学计算与深度学习库、可以做到开箱即用但体积大,并且很多的东西我们在刚开始学是用不上的,而 Miniconda 只包含最小的 conda 与 Python,需要什么再自己安装、体积小且更灵活。所以选用miniconda。
网页搜索miniconda就可以了,或者打开这个链接Miniconda – Anaconda,miniconda有很多版本,我们点击https://repo.anaconda.com/miniconda下载以前的版本呢,太新的版本往往意味着有很多不稳定性🤣。
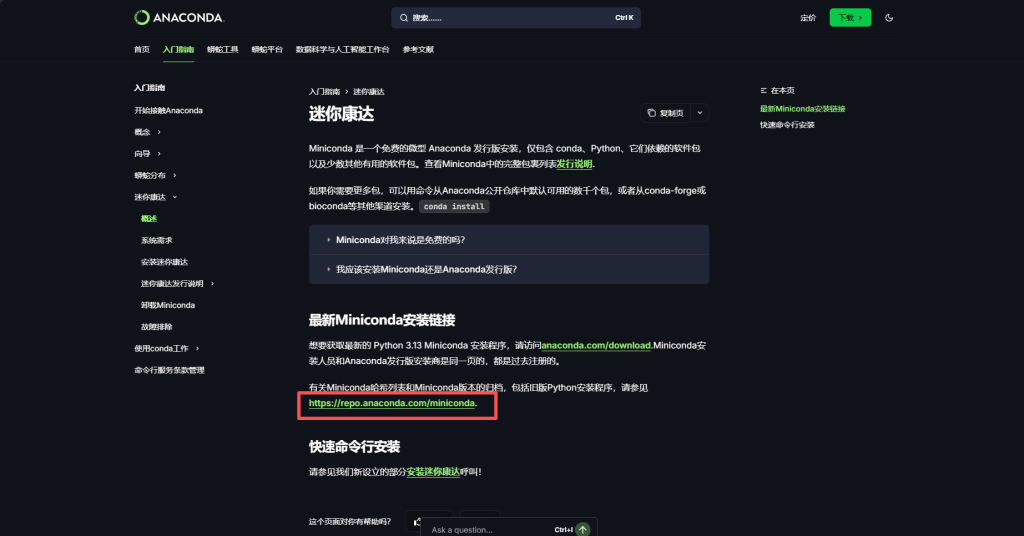
我选择下载这个miniconda-py39的版本Miniconda3-py39_25.9.1-3-Windows-x86_64.exe,因为他的修改日期比较有意思。大家可以自己看着下载,都差不多。
一直next就可以了,这里注意一下选择Just Me,可以避免一些问题。这个是ai的解释一般选 Just Me —— 安装在自己用户目录下,不需要管理员权限,最稳妥也最不容易出权限和环境冲突问题;只有在多用户共用同一台机器、并且你明确需要所有账户共享 conda 时,才选 All Users。
视频里选了all users,我感觉不对看了其他视频然后又问了ai,所以这里选just me。
记一下你下载的位置呢,方便以后自己来查看。我喜欢装在其他盘上,看你们自己呢。
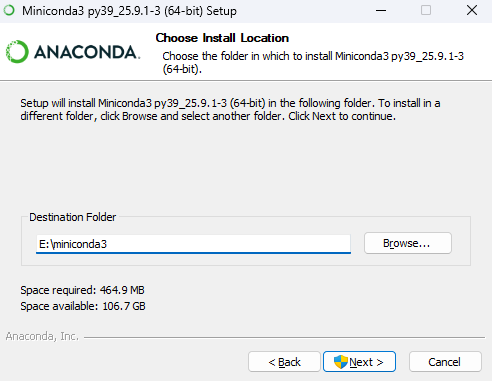
这里全选呢。选了第二个可以将miniconda添加Windows的环境变量里,方便我们在在哪里都可以用conda命令呢,最后点击安装就好了。
然后打开终端输入conda env list就可以查看我们现在又的环境了,如果我们在上一步没勾选第二个的话,这里是不能直接在系统终端里实现conda命令的,需要在anaconda自带的终端里才能用呢。

安装pytorch
安装CUDA最重要的就是版本对应,不然会有乱七八糟的问题出现呢,具体的原因我在上面理论部分的第三个问题回答了呢。
首先我们查看一下我们电脑最高能装多少版本的CUDA,win+R输入cmd打开终端,在终端中输入nvidia-smi,这上面显示了我能安装的CUDA版本最高的就是12.7。
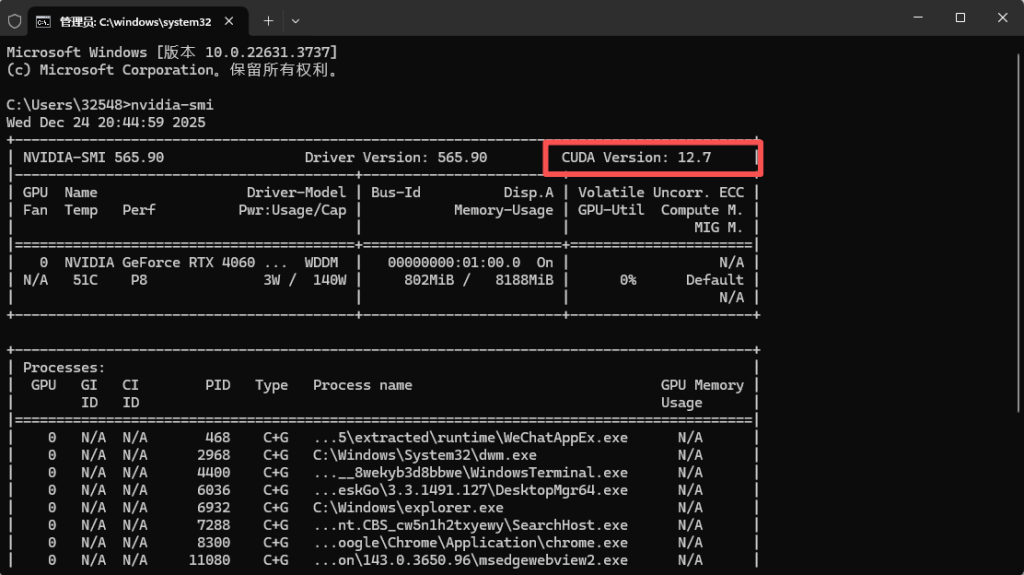
然后我们浏览器搜索PyTorch,点击Get started,通过pytorch来下载cudatoolkit和cudnn呢,这样就不需要去英伟达的官网去下载,然后再配置环境了,节省了步骤。
点击Previous PyTorch Versions之前的PyTorch版本,还是不要下载最新的呢,下载以前的版本。
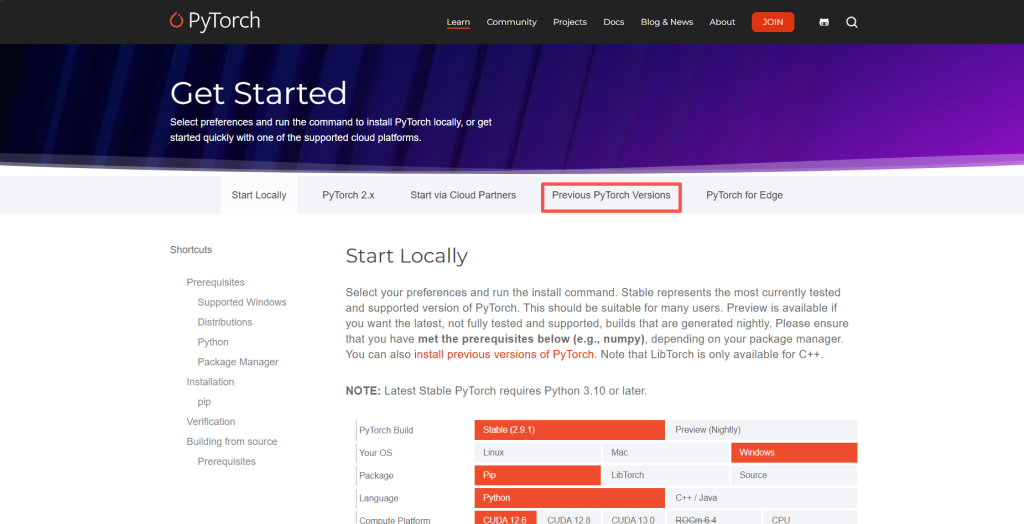
我选择的是pytorch2.5的版本,cuda是11.8的,conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia
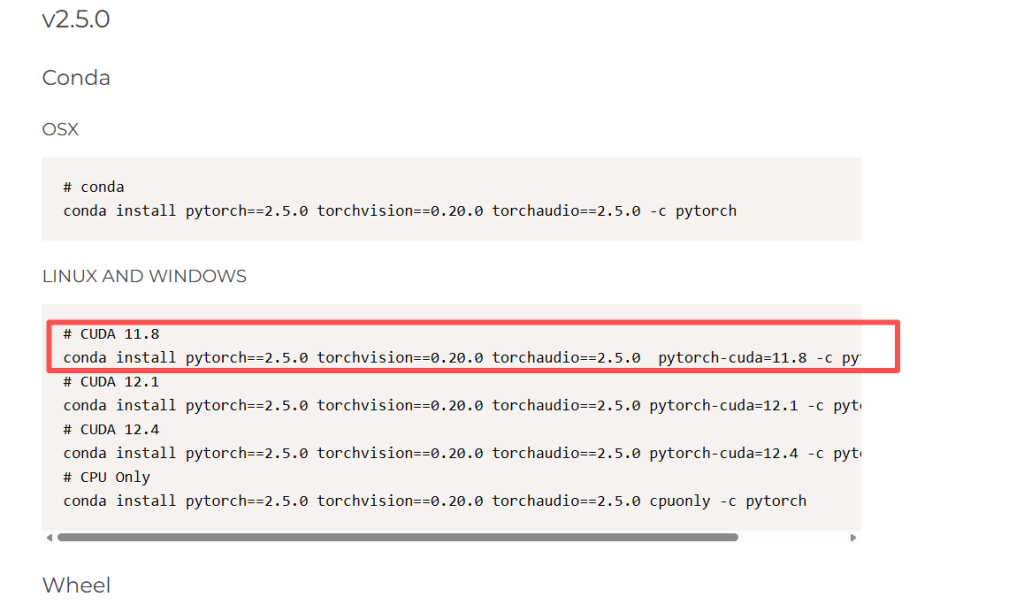
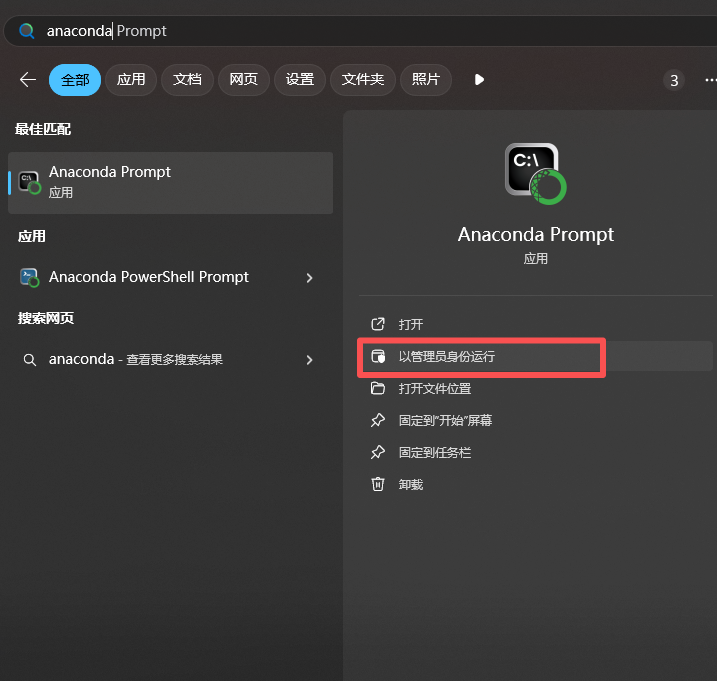
然后以管理员身份运行anaconda prompt。
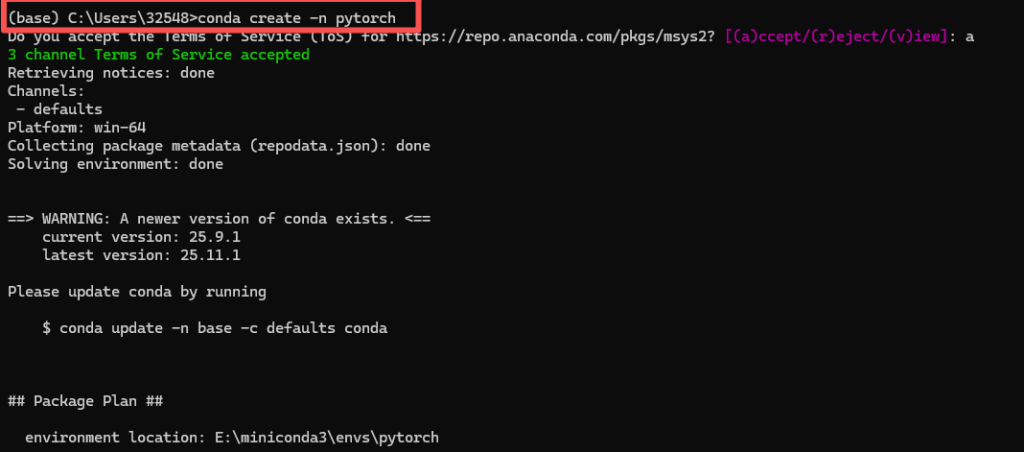
输入conda create -n pytorch来创建一个新的环境,-n后面是你的环境的名称,你可以自己取的。
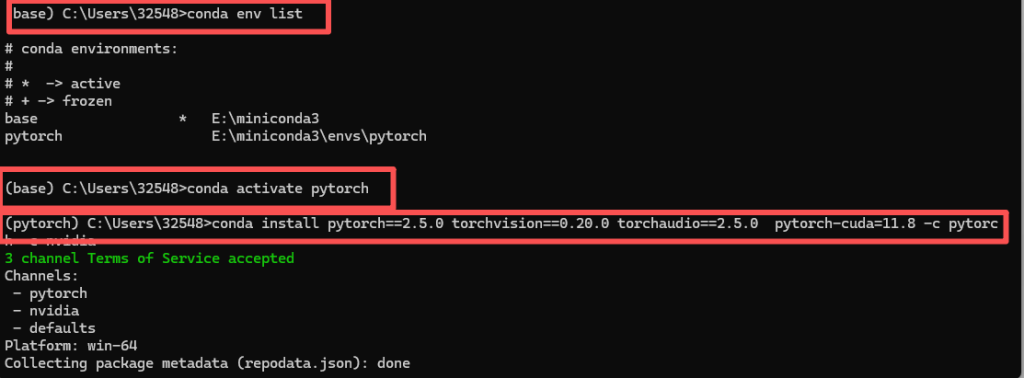
然后输入conda env list就可以查看我们刚刚创建的环境了,再输入conda activate pytorch就可以激活我们的环境了,activate后面就是环境的名字。输入刚才我们再pytorch官网找到的代码,就可以开始下载了。
然后我们可以输入python来打开python看看我们有没有安装成功呢。依次输入下面的代码来查看
import torch
print("torch:", torch.version)
print("cuda available:", torch.cuda.is_available())
print("cuda version:", torch.version.cuda)
print("cudnn:", torch.backends.cudnn.version())
print("gpu:", torch.cuda.get_device_name(0))
如果都有输出,并且cuda availablel: True说明我们安装成功了呢😘。
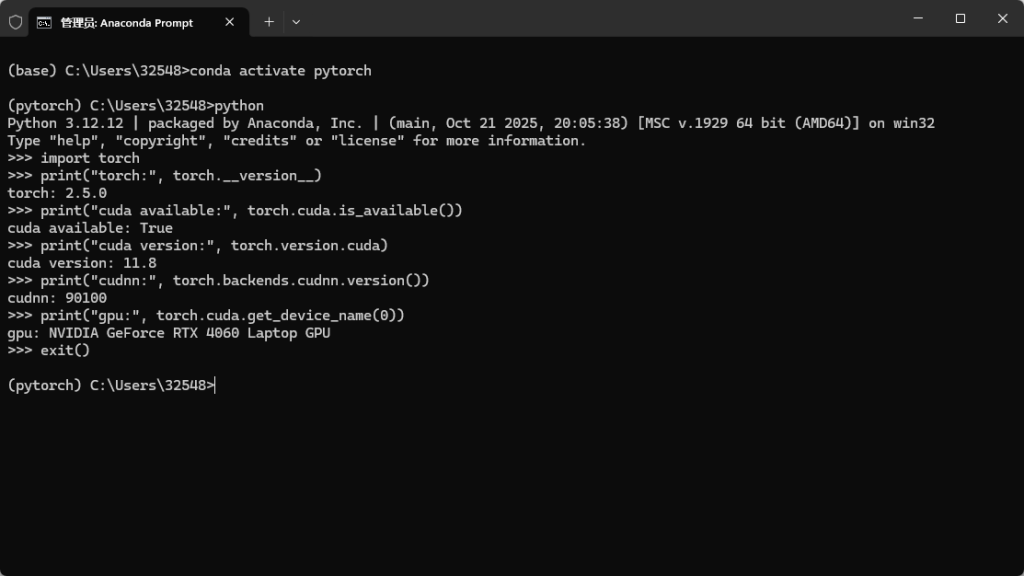
最后说一下怎么在Vscode里使用这个环境呢,点击界面的右下角的版本号,在上面就会显示你有的所以版本信息,选用你用conda创建的环境就行了。
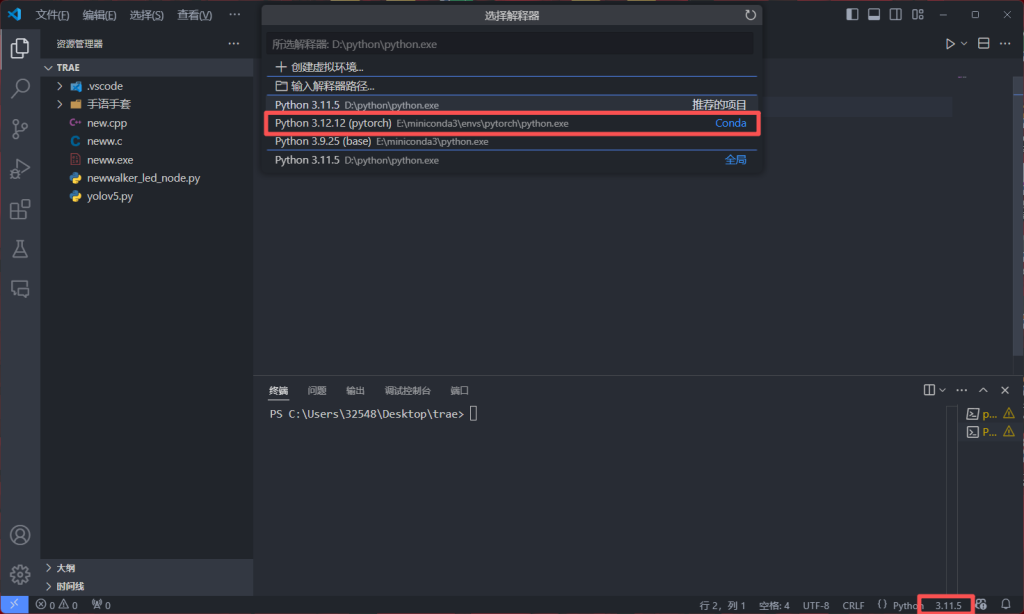
下面就是运行结果。
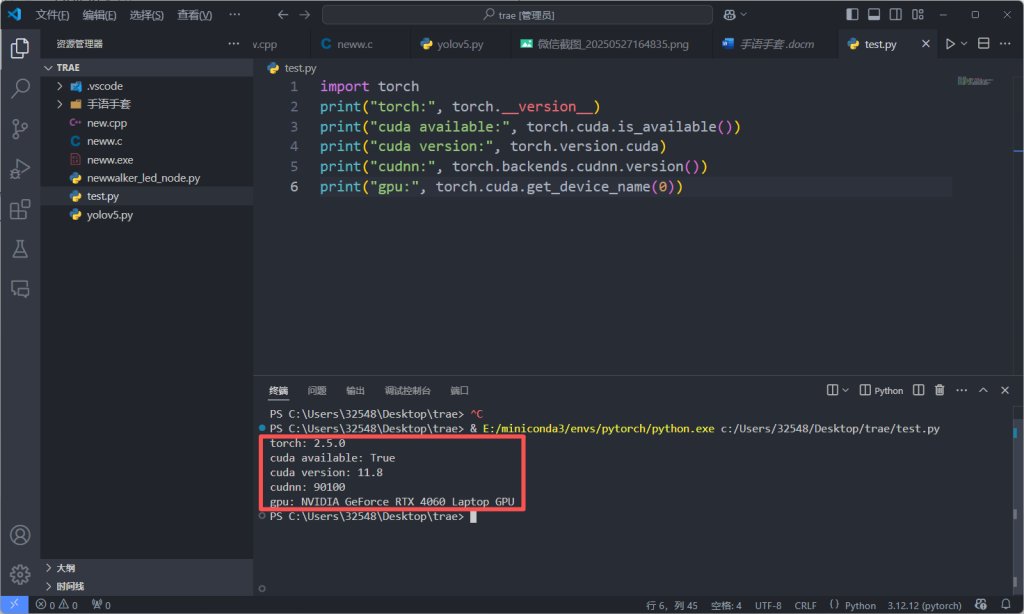
追加一下
如果你点击运行时会弹出命令行窗口闪一下,然后才能运行的情况。
这个是因为我们终端默认是用了PowerShell,这个在运行的时候会进行一些Windows的配置,不是很方便,我们换成command prompt的就好多了。
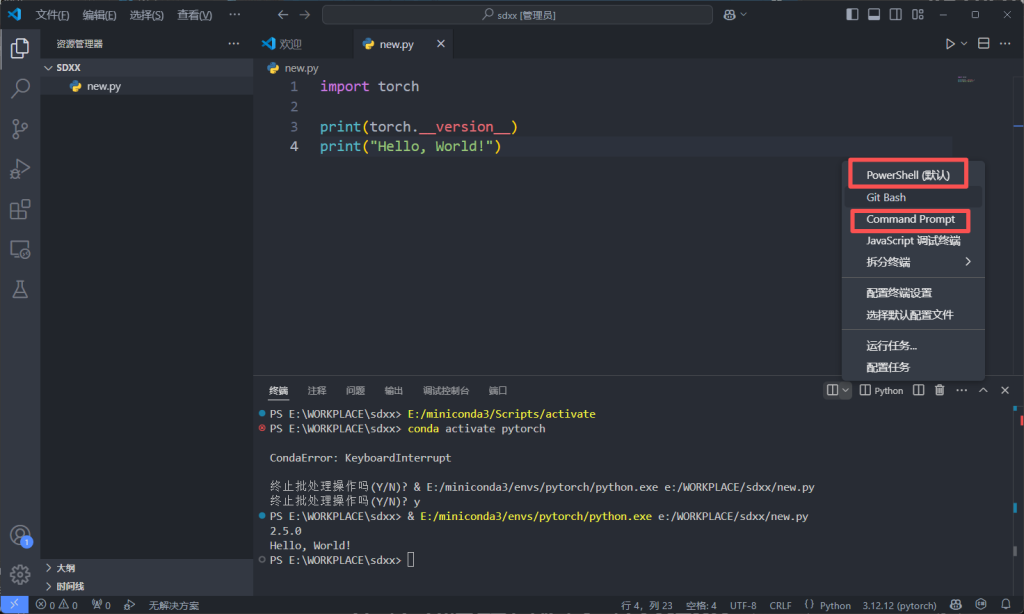
键盘输入ctrl+shifl+P,然后输入teminal:select default profile选择。
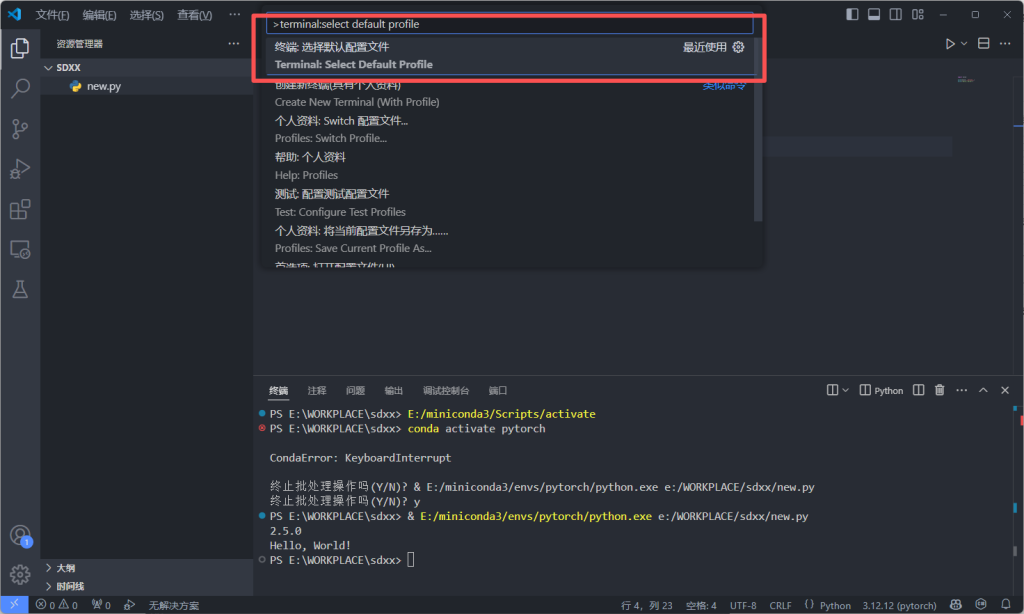
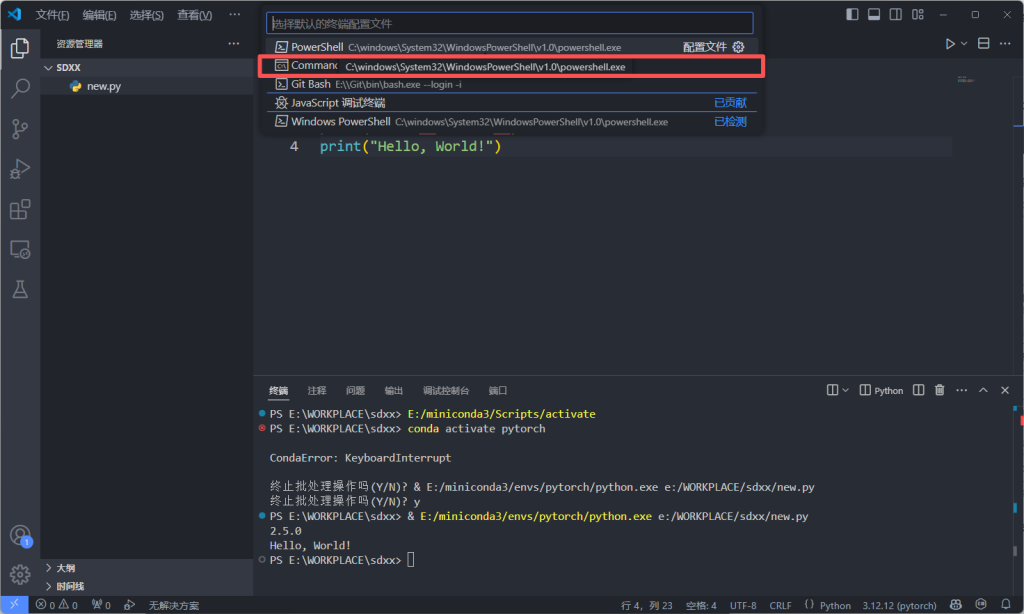
然后点击command prompt,这样就配置好了。
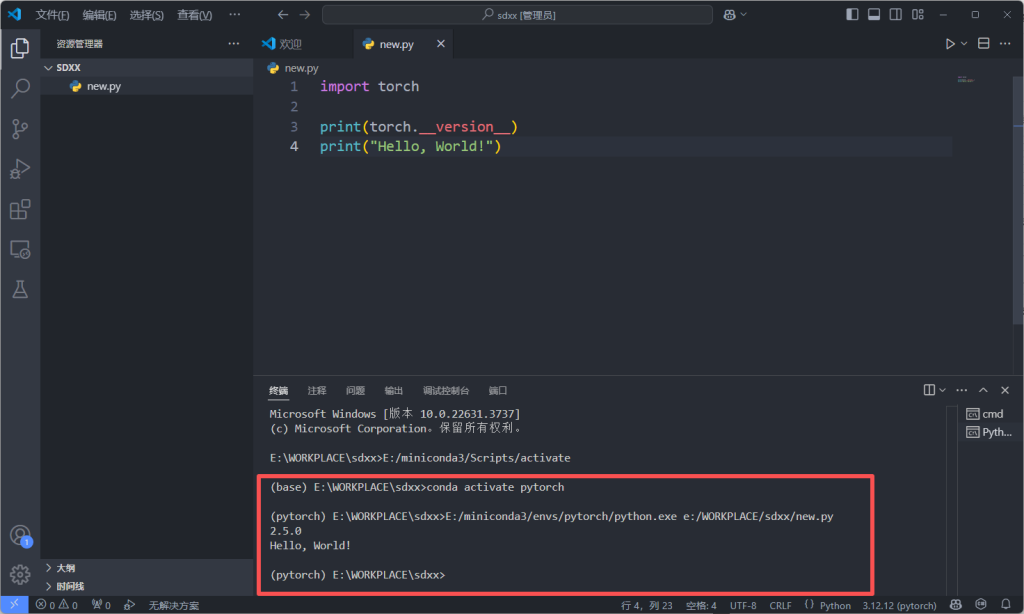
然后关闭之前的终端,重新运行就会发现没有命令行窗口弹出了。

评论(0)
暂无评论